

Objective
Apache logs are a common source of log data that almost every organization analyzes. Access logs are used both by IT and Marketing to understand what is being accessed, when and by whom. Error logs provide valuable information about the health and performance of their servers and the applications run on them.
Typically, due to storage constraints, these logs are rotated out and archived into low cost cloud storage like Amazon S3 or Microsoft Azure Blob. Sometimes, it becomes necessary to revisit these files after initial analysis for security purposes, or deeper dives into customer behavior, or to enrich with other data sources.
Although there are plenty of tools out there to analyze logs, both in real-time and batch, these solutions are not readily capable of analyzing large quantities of Apache logs that have been compressed, archived and stored in cloud storage. Among the many issues archived files in the cloud present are:
- Large overall data set size
- Target data can be spread across multiple files, in different directories and/or buckets
- Decompression of compressed files slows down data processing
- Significant data cleansing is required due to high occurrence of errors, duplicates, or omissions in the data
With Essentia, preparing and analyzing vast amounts of archived log data is easily performed.

1. Process & Analyze In-Place
Essentia can connect to cloud data stores like Amazon S3, and allow you to explore log data in-place and as-is across any number of directories or across different buckets. Even compressed data can be sampled as is eliminating time consuming decompression. Virtualize your data by creating rule-based categories that provides a flexible, adaptive and iterative framework for data processing and analysis jobs.

2. Log Specific Tools
Log specific parsing tools allow you easily convert the format of any log into a more cleanly delimited version that is analysis ready. Streaming unzip feature enables directly working with compressed logs, allowing you extract only data fields that are relevant to analysis. Cleansing, deduping, error correction and data tranformation can be performed on the fly in a schema on read process.

3. Scale Out or Up Seamlessly
A single node can accomplish many of your analysis needs. But when you need to be able to achieve certain levels of performance, Essentia can be run distributed as a cluster in the cloud. Performance is linear, so to double the performance, you simply add twice as many nodes of the same type. You can also choose virtual machines with higher specifications to achieve even greater performance gains.
Analysis & Visualization


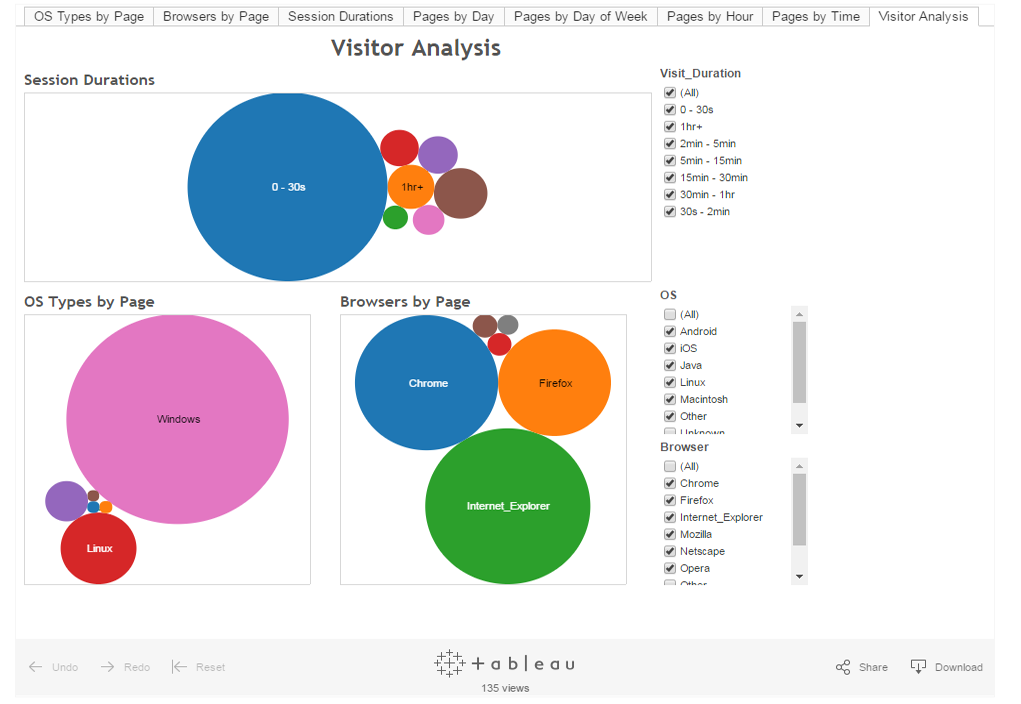
AuriQ Essentia easily integrates with many of today’s popular BI and visualization tools including Tableau, Qlikview, Excel, R, and more to quickly gain understanding from your logs.
For example, your data from the cloud can be efficiently parsed, cleaned, and reduced directly into Tableau Extract files (.tde) to generate interactive and compelling visualizations as shown in the examples above.
You can also directly load your prepared log data into any other analytic platform or relational database like Amazon Redshift, MySQL, or Hadoop as part of your data pipeline.
Find out more about analyzing Apache logs in the documentation or view script samples in our github repository.