Extract, Transform, Load
Raw to ready in minutes or hours instead of days or weeks

Essentia can accelerate your ETL workflow, especially when working with semi-structured or completely unstructured data. It reduces the number of steps to go from raw data to cleansed and normalized data, and it does so without ever moving or modifying the original data files. In addition to simplified workflow, Essentia’s scalable architecture allows any ETL job to be seamlessly split across multiple nodes, with linear scalability that makes it easy to estimate how much more compute resources need to be applied to achieve a specific performance target.

1. Data Collection
Data is pushed or pulled from source systems (optionally compressed) and stored in cloud based object storage.
No ETL or pre-processing needs to be performed prior to storage, and data can be left in original state and format for the entirety of future data processing and analysis operations. This ensures data immutability.

2. Exploring the Data
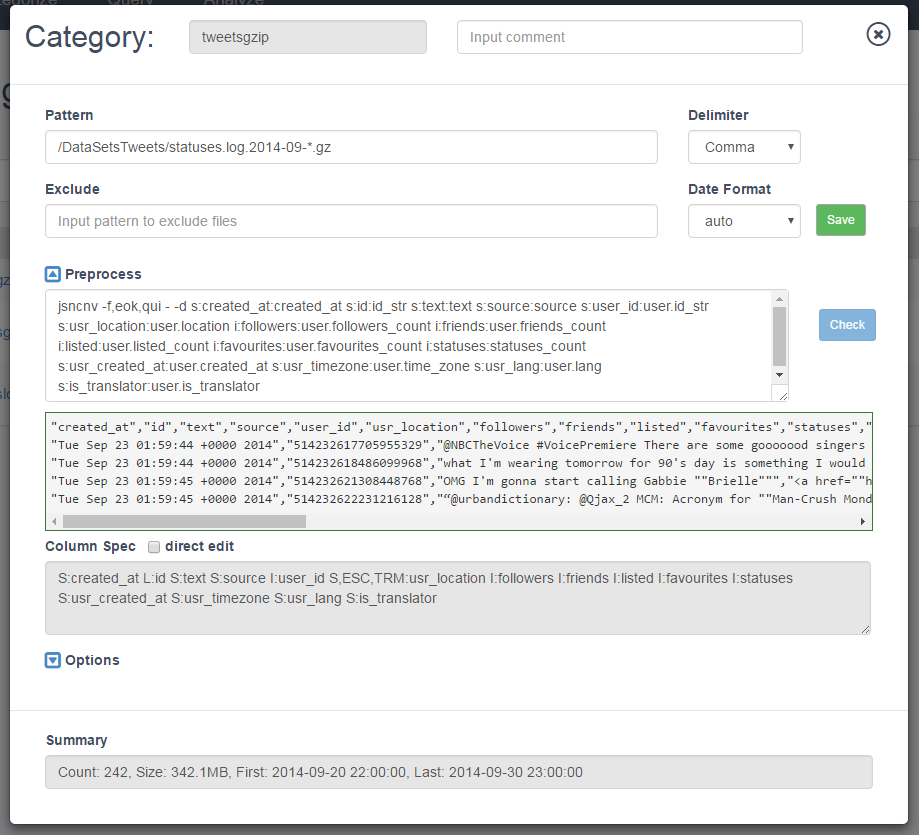
Users can validate completeness of target data by using the explorer and categorization tools to get counts of number of files, date ranges covered, and data samples.
When ready, solidify rule based virtual data categories that map back to the original files in object storage.

3. Preparing Data
Trial preprocessing rules on virtualized data and view sample outputs to see if they produce the desired output. This can be done on a single category or multiple categories.
You can also join data sets as well as apply data transformations on these combined data sets.
Iterative Data Transformations at Scale
Once all the preprocessing and transformation rules are worked out, you can apply it to all the data in your target categories or to a subsection of them based on specified criteria (for example date/time range or logged event). If the amount of data that needs to be processed is very large and would take too long on a single machine, then it’s very easy to assign additional worker nodes to distribute the workload.
With Essentia, target data is streamed directly from the raw files in cloud storage, cleansed and normalized on the fly, and then either outputted to file, loaded into an in memory db or piped directly to some other analytic tool.
Find out more in our documentation section for ETL samples.